Java Stream流使用
Summary::
定义
流(Java Stream)简短的定义就是“从支持数据处理操作的源生成的元素序列”。
- 元素序列——就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如ArrayList 与 LinkedList)。但流的目的在于表达计算,比如 filter、sorted 和 map。
- 源——流会使用一个提供数据的源,比如集合、数组或 I/O 资源。 请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
- 数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,比如 filter、map、reduce、find、match、sort 等。流操作可以顺序执行,也可以并行执行。
特点
- 流水线——很多流操作本身会返回一个流,这样多个操作就可以链接起来,构成一个更大的流水线。这使得下一章中将要讨论的一些优化成为可能,比如处理延迟和短路。流水线的操作可以看作类似对数据源进行数据库查询。
- 内部迭代——与集合使用迭代器进行显式迭代不同,流的迭代操作是在后台进行的。
流只能遍历一次,遍历完后就消费掉了.
高性能
Streams 库的内部迭代可以自动选择一种适合你硬件的数据表示和并行实现。与此相反,一旦选择了 for-each 这样的外部迭代,那你基本上就要自己管理所有的并行问题了(自己管理实际上意味着“某个良辰吉日我们会把它并行化”或“开始了关于任务和 synchronized 的漫长而艰苦的斗争”)。
使用
流操作
流操作分为两类: 中间操作和终端操作
中间操作
一些操作会返回一个流,例如filter,sorted. 可以多个这样的操作连接起来.
重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理——它们很懒。这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理。

终端操作
终端操作会从流的流水线生成结果,其结果是任何不是流的值,比如 List、Integer,甚至 void。

流的一般使用流程
- 一个数据源(如集合)执行一个查询
- 一个中间操作链
- 一个终端操作
使用的样例代码见计算机系统学习demo-stream
筛选
用谓词筛选
menu.streamisVegetarian).collect(toList();
筛选各异的元素
.distinct(),使用equals方法比较
切片
java9 对排序的流截断
takeWhile和dropWhile
截断
limit(n)选择头n个元素
skip(n)选择头n个元素
注意: 在筛选和切片合用时,顺序对结果有影响.
映射
对流每一个元素应用函数: map()
List<String> dishNames = menu.streamgetName).collect(toList();
流的扁平化: flatMap()
对于给定需求: 对于一个单词列表,列出里面各不相同的字符.
words.stream().map(word -> word.split("")).distinct().collect(toList());不能满足,因为得到的是List<String[]>
words.stream().map(word -> word.splitstream).distinct().collect(toList();不能满足,因为得到的是List<Stream<String>>.
正确方法:
List<String> uniqueCharacters =words.stream().map(word -> word.splitstream).distinct().collect(toList();
使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用mapstream时生成的单个流都被合并起来,即扁平化为一个流
同理以下方法可以合并List<List>对象为单个List:
List mergedList = listList.streamstream).collect(Collectors.toList()
元素匹配谓词
判断流中元素是否满足某个条件。匹配函数接收Java Predicate(即谓词,是函数式接口,做条件判断)作为参数.
anyMatch():流中是否有一个元素能匹配给定的谓词,只要有一个就返回true
allMatch():流中是否所有元素能匹配给定的谓词,只要有一个不匹配就返回false
noneMatch():流中是否所有元素能不匹配给定的谓词,只要有一个匹配就返回false
三个操作都会短路求值(在能够确定结果的时候就返回而不是每次都全部计算)
规约(reduce)
规约是一种聚合操作,对传入的N个数据,使用一个二元的符合结合律的操作符⊕,生成1个结果。这类操作包括取最小、取最大、求和、平方和、逻辑与/或、向量点积。规约也是其他高级算法中重要的基础算法。
reduce()方法的工作原理可以分为以下几个步骤:
- 初始化:如果有初始值参数,那么这个初始值就是归约操作的起点。如果没有提供初始值,那么流中的第一个元素将作为起点。
- 合并:对于流中的每个元素,都会调用累加器函数(accumulator),这个函数定义了如何将当前元素与之前的累积结果合并。
- 迭代:流中的每个元素都会依次通过累加器函数进行处理,直到流中的所有元素都被处理完毕。
- 结果:最终,所有的元素都经过累加器函数处理后,会得到一个单一的结果值。
reduce()方法的用法
reduce()方法有几个不同的重载版本,以下是其中最常见的几个:
Optional<T> reduce(BinaryOperator<T> accumulator):这个版本不接受初始值,如果流为空,则返回一个空的Optional对象。T reduce(T identity, BinaryOperator<T> accumulator):这个版本接受一个初始值,如果流为空,则返回这个初始值。<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner):这个版本用于并行流,它接受一个初始值、一个累加器函数和一个组合器函数,用于在并行流中合并部分结果。
数值流
为了避免int,long,double这类原始类型的自动装箱拆箱带来的性能损耗,Stream 提供了基本数值类型专用的API: IntStream、DoubleStream和LongStream
map变成了mapToInt、mapToDouble和mapToLong。
Optional类变成了OptionalInt、OptionalDouble和OptionalLong。
将IntStream转换为Stream<Integer>: Stream<Integer> stream = intStream.boxed();
创建流
使用of函数: Stream<String> stream = Stream.of("Java 8 ", "Lambdas ");
空流: Stream<String> emptyStream = Stream.empty();
从数组转换流: int[] numbers = {1, 2, 3, 4, 5}; int sum = Arrays.stream(numbers).sum();
由文件创建流
java.nio.file.Files中的很多静态方法都会返回一个流。例如,一个很有用的方法是Files.lines,它会返回一个由指定文件中的各行构成的字符串流
// 统计文件不同单词数量
long uniqueWords = 0;
Stream<String> lines =
Files.lines(Paths.get("README.md"), Charset.defaultCharset());
uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" ")))
.distinct()
.count();
System.out.println("Unique words: " + uniqueWords);
从函数创建无限流
方法1: Stream.iterate
样例:
Stream.iterate(0, n -> n + 2)
.limit(10)
.forEachprintln;
iterate方法接受一个初始值,还有一个依次应用在每个产生的新值上的Lambda(UnaryOperator<t>类型,表示对单个操作数的操作,该操作数生成与其操作数类型相同的结果。这是针对操作数和结果类型相同的情况的专用化 Function )。
下方是UnaryOperator和Function类。根据函数式接口的定义可知iterate方法每次调用的是UnaryOperator.apply()方法。仔细观察他们的泛型类发现,Function 的apply接口入参和返回值类型不一样,而UnaryOperator的apply接口入参和返回值类型是一样的
@FunctionalInterface
public interface UnaryOperator<T> extends Function<T, T> {
static <T> UnaryOperator<T> identity() {
return t -> t;
}
}
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
该方法产生一个无限流,如果不使用limit限制,会一直计算下去。
方法2:Stream.generate
接受一个Supplier<T>类型的Lambda提供新的值。
样例:
Stream.generaterandom
.limit(10)
.forEachprintln;
收集数据
规约和汇总
collect()是流的终端操作中最常用的也是功能最丰富的,可以将流中元素收集到不同的数据结构中,如列表、集合、映射或自定义对象。reduce()函数可以当做collect函数的一个特例。
collect接受一个Collector类作为参数。Collector泛型接口重要方法如下
// T是要收集的项目的泛型,A是累加器的类型,累加器是在收集过程中用于累积部分结果的对象,R是收集操作得到的对象(不一定是集合)的类型。
public interface Collector<T, A, R> {
// 返回一个Supplier,不接受参数,返回一个容器A,作用为构造一个空的结果容器并返回
Supplier<A> supplier();
// 返回一个BiConsumer,接收两个参数,返回空,功能为把T类型对象装入容器A中
BiConsumer<A, T> accumulator();
// 返回一个BinaryOperator,接收两个A类型容器,并把他们合并为一个新的A类型容器
BinaryOperator<A> combiner();
// 返回一个Function,接收一个A类型容器,返回一个R类型的容器(即collect函数的返回结果)
Function<A, R> finisher();
Set<Characteristics> characteristics();
}
Collectors工厂类提供多种预定义的收集器,可以直接调用创建方法。也可以使用自定义的Collector。
Collectors中还有一类预定义方法,例如summarizingInt,把一个整型流收集成:IntSummaryStatistics{count=9, sum=4300, min=120,average=477.777778, max=800}。对于数值基本类型都有类似方法。
Collectors也预定义了reducing方法,.collectreducing)和.reduce(功能几乎一样。关于Collectors的详细信息见官方文档
Collectors还定义了collectingAndThen,它允许你将一个收集器的结果传递给一个函数进行进一步处理。一个有用的技巧就是可以在收集器返回为Optional时调用get。
分组
Collectors中定义了groupingBy函数,接受一个类型为Function的函数式接口参数,功能为分类器,把流转成多个子流。 第二个参数可以接收一个Collector,对子流进行收集。该函数的重载函数版本中无需指定收集器,固定为toList,把流分组收集为Map<<K,List<V>。
如果接收collector参数为
- grouping: 可以进行二级分组甚至多级分组;
- counting: 可以计数每组元素个数:
- 接受maxBy可以获取每组最大值;。
分区
分区是分组的特殊情况。Collectors中定义了partitioningBy函数:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函数。分区函数返回一个布尔值,这意味着得到的分组Map的键类型是Boolean。
样例: Map<Boolean, List<Dish>> partitionedMenu = menu.streamisVegetarian);
自定义收集器
通过收集为列表的ToListCollector案例体会。
明确泛型
Collector是一个泛型接口,实现收集器Collector接口,首先需要明确泛型类。
ToListCollector在功能上是把一个Stream<T>的流转换为List<T>,这其中累加的过程用到的累加器也是List<T>。所以在确定一个ToListCollector时不需要像Collector<T, A, R>接口指定三个类,只需要指定流对象T就够了。所以定义为:public class ToListCollector<T> implements Collector<T, List<T>, List<T>>
实现supplier()
supplier()作用为构造一个空的结果容器并返回。
在ToListCollector中,累加器需要的容器是List<T>,所以返回一个ArrayList的构造器即可。
实现accumulator()
accumulator()作用为把T类型对象装入A类容器中生成并返回一个新的A类容器
在ToListCollector中,累加器的容器类型是List<T>,每次累加需要把新的元素放入容器,所以return List::add;即可。
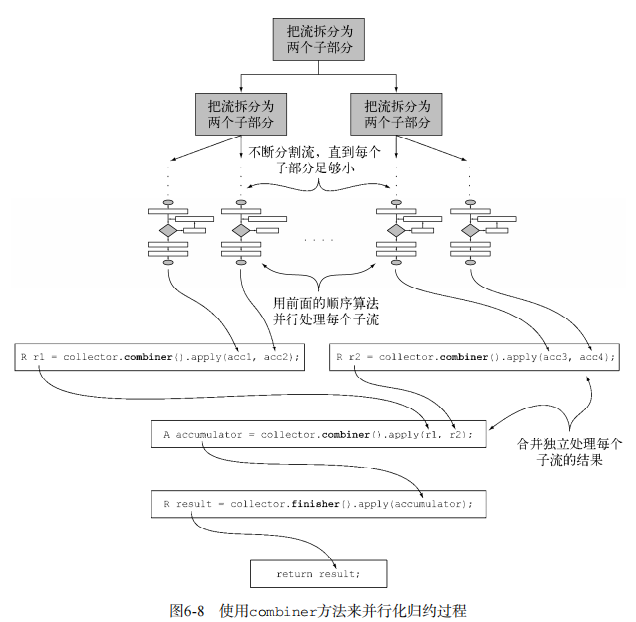
实现combiner()
combiner()主要功能是合并两个部分结果,这两个部分结果都是通过累加器函数处理流中的元素得到的。
在ToListCollector中,合并结果方法就是合并两个List。所以return (list1, list2) -> {list1.addAll(list2);return list1;};即可。
实现finisher()
finisher()返回在累积过程的最后要调用的一个函数,以便将累加器对象转换为整个集合操作的最终结果。
在ToListCollector中,累加器对象恰好符合预期的最终结果,因此无需进行转换。所以return Function.identity();即可。identity()函数会直接返回接受的参数。
如果是要统计列表元素个数,就需要调用List::size做转换。
实现characteristics()
characteristics返回一个不可变的Characteristics集合,它定义了收集器的行为——尤其是关于流是否可以并行归约,以及可以使用哪些优化的提示。Characteristics是一个包含三个项目的枚举。
以下是 Collector.Characteristics 中定义的一些主要特征:
| 特征 | 描述 |
|---|---|
CONCURRENT |
表示收集器是并发的,这意味着结果容器可以支持与来自多个线程的相同结果容器同时调用的累加器函数。如果 CONCURRENT 收集器也不是 UNORDERED,则只应在应用于无序数据源时同时进行评估。 |
UNORDERED |
指示集合操作不承诺保留输入元素的遭遇顺序。如果结果容器没有内在顺序(例如 Set),则可能是这样。 |
IDEMPOTENT |
表示累加器函数是幂等的,即多次应用相同的元素到同一个累加器上不会改变最终结果。 |
IDENTITY_FINISH |
表示累加器函数的最终结果可以直接作为收集器的输出,不需要调用 finisher 函数。 |
这些特征可以在创建自定义收集器时使用,也可以在选择预定义的收集器时考虑。例如,如果你正在处理一个并行流,并且你的收集器支持并发处理,那么你可以期望更好的性能,因为多个线程可以同时向结果容器添加元素。
在实际应用中,了解这些特征可以帮助你做出更明智的决策,比如是否应该使用并行流,或者是否需要对结果进行排序。此外,这些特征还可以帮助JVM优化收集器的执行,例如,如果知道收集器是幂等的,JVM可能可以跳过某些优化步骤。
如果需要优化,可以挑选需要的,例如return Collections.unmodifiableSet((EnumSet.of(IDENTITY_FINISH, CONCURRENT)));
如果不需要这些特殊优化,可以返回空集合:return Collections.emptySet();
参考文献
Java8实战4-6章